
Hello there! I am Moayed Haji Ali, a PhD student in Computer Science at Rice University, working on multimodal generative modeling under the supervision of Prof. Vicente Ordonez. I am currently a Research Intern at the amazing Snap Inc.’s Creative Vision Team, working with Willi Menapace, Aliaksandr Siarohin, and Sergey Tulyakov where I work on generative AI research. Prior to my PhD, I obtained my undergraduate degree from Koç University, in Turkey, where I worked with Prof. Aykut Erdem.
My research interests focus on image, video, and audio generation and cross-modal generation. I am particularly interested in bringing new capabilities to existing generative models.
🔥 News
- 2026.02: 🎉🎉 Omni-Attribute was accepted at CVPR 2026
- 2026.02: 🎉🎉 EgoEdit was accepted at CVPR 2026
- 2026.02: 🎉🎉 ELIT was accepted at CVPR 2026
- 2026.01: 🎉🎉 Sprint was accepted at ICLR 2026
- 2025.09: 🎉🎉 DFM was accepted at NeurIPS 2025
- 2025.09: 🎉🎉 CFred was accepted at WACV 2026
- 2025.06: 📄 [New Work] DFM published on arXiv
- 2025.06: 🎉🎉 AV-LINK was accepted at ICCV 2025
- 2024.12: 📄 [New Work] AV-LINK published on arXiv
- 2024.06: 📄 [New Work] GenAU published on arXiv
- 2024.06: 🎉🎉 ElasticDiffusion paper presented at CVPR 2024
- 2024.03: 🚀 Joined Snap Inc. Creative Vision Team as Research Intern
- 2023.11: 📄 [New Work] ElasticDiffusion preprint released on arXiv
- 2023.10: 🎉🎉 VidStyleODE presented at ICCV 2023
- 2023.08: 🚀 Started PhD journey at Rice University under Prof. Vicente Ordonez
- 2023.06: 🚀 Graduated from Koc University, third in my department.
📝 Publications

One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers
Moayed Haji-Ali, Willi Menapace, Ivan Skorokhodov, Dogyun Park, Anil Kag, Michael Vasilkovsky, Sergey Tulyakov, Vicente Ordonez, Aliaksandr Siarohin
- A drop-in DiT-compatible mechanism that decouples input image size from compute via a learnable variable-length latent interface, enabling dynamic latency-quality trade-offs at inference time.
Omni-Attribute: Open-vocabulary Attribute Encoder for Visual Concept Personalization
Tsai-Shien Chen, Aliaksandr Siarohin, Guocheng Gordon Qian, Kuan-Chieh Jackson Wang, Egor Nemchinov, Moayed Haji-Ali, Riza Alp Guler, Willi Menapace, Ivan Skorokhodov, Anil Kag, Jun-Yan Zhu, Sergey Tulyakov
- First open-vocabulary image attribute encoder that learns high-fidelity, attribute-specific representations for personalization and compositional generation.
EgoEdit: Dataset, Real-Time Streaming Model, and Benchmark for Egocentric Video Editing
Runjia Li, Moayed Haji-Ali, Ashkan Mirzaei, Chaoyang Wang, Arpit Sahni, Ivan Skorokhodov, Aliaksandr Siarohin, Tomas Jakab, Junlin Han, Sergey Tulyakov, Philip Torr, Willi Menapace
- A complete ecosystem for egocentric video editing featuring a curated dataset, a real-time streaming editor, and an evaluation benchmark for instruction-guided editing under egomotion.
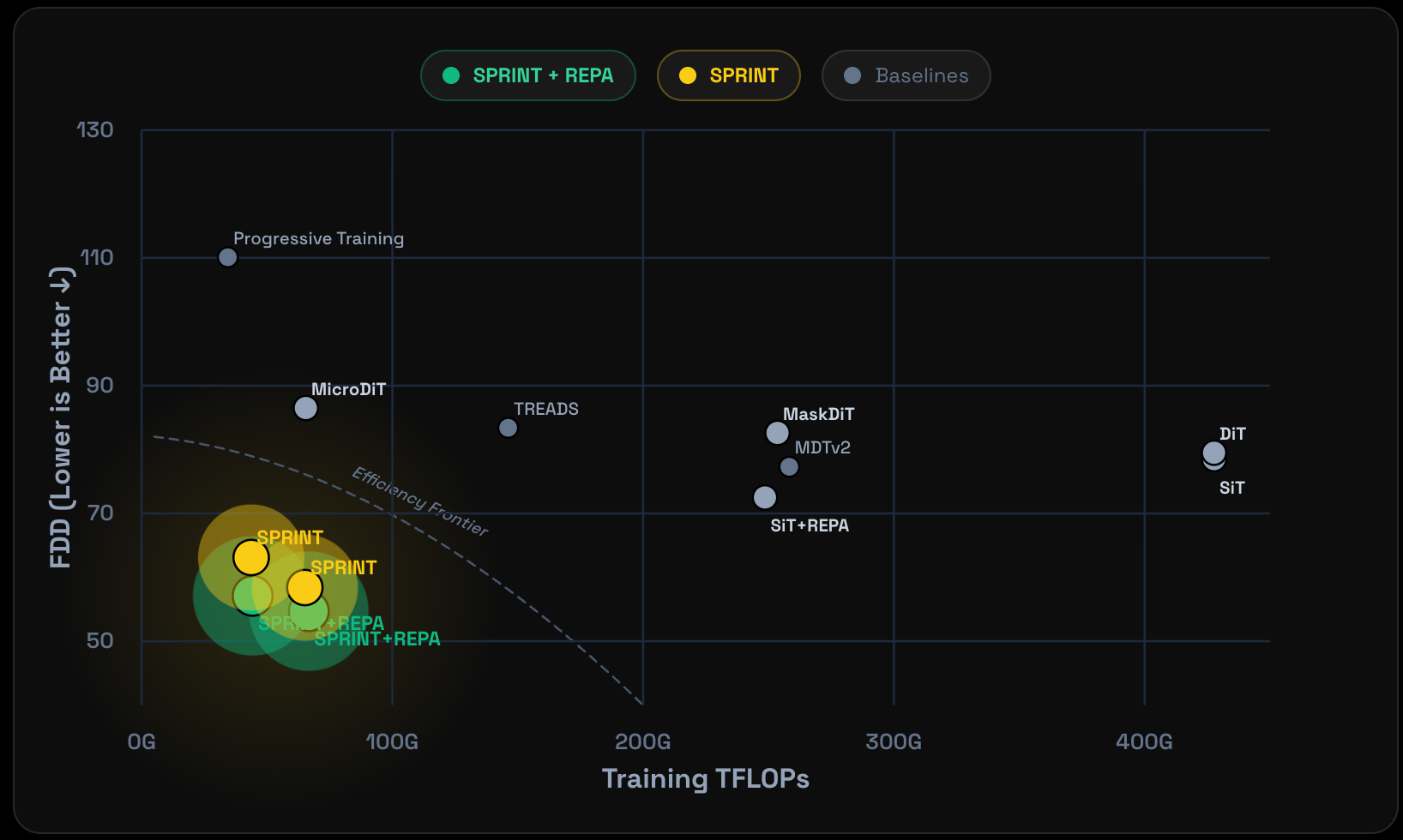
Sprint: Sparse-Dense Residual Fusion for Efficient Diffusion Transformers
Dogyun Park, Moayed Haji-Ali, Yanyu Li, Willi Menapace, Sergey Tulyakov, Hyunwoo J. Kim, Aliaksandr Siarohin, Anil Kag
- Enables aggressive token dropping (up to 75%) in diffusion transformers while preserving quality through sparse-dense residual fusion, achieving 9.8x training savings.
Taming Data and Transformers for Audio Generation
Moayed Haji-Ali, Willi Menapace, Aliaksandr Siarohin, Guha Balakrishnan, Sergey Tulyakov, Vicente Ordonez
- Introduces AutoCap for automatic audio captioning and GenAu architecture for scalable transformer-based audio generation.
Improving Progressive Generation with Decomposable Flow Matching
Moayed Haji-Ali, Willi Menapace, Ivan Skorokhodov, Arpit Sahni, Sergey Tulyakov, Vicente Ordonez, Aliaksandr Siarohin
- Framework for progressive generation of visual media, improving visual quality for both images and videos through decomposable flow matching.
AV-LINK: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation
Moayed Haji-Ali, Willi Menapace, Aliaksandr Siarohin, Ivan Skorokhodov, Alper Canberk, Kwot Sin Lee, Vicente Ordonez, Sergey Tulyakov
- Unified framework for video-to-audio and audio-to-video generation, leveraging frozen diffusion models for temporally-aligned cross-modal conditioning.

Moayed Haji-Ali, Guha Balakrishnan, Vicente Ordonez
- Training-free method for generating images of arbitrary sizes using pre-trained diffusion models through global-local content separation.
VidStyleODE: Disentangled Video Editing via StyleGAN and NeuralODEs
Moayed Haji Ali, A. Bond, T. Birdal, D. Ceylan, L. Karacan, E. Erdem, A. Erdem
- A novel framework for modeling videos using pre-trained image generators and learned latent ODEs, enabling high-resolution video editing applications including image animation, guided motion and appearance manipulation, and temporal interpolation.
- Jaywon Koo, Jefferson Hernandez, Moayed Haji Ali, Ziyan Yang, Vicente Ordonez “Evaluating Text-to-Image Synthesis with a Conditional Fréchet Distance” WACV 2025
- Yehya Hassanzadeh-Nazarabadi, Moayed Haji Ali, Nazir Nayal “Opera: Scalable Simulator for Distributed Systems” IEEE INFOCOM 2021
📖 Service
- CVPR 2025, Reviewer
- ECCV 2024, Reviewer
- NeurIPS 2024/2025, Reviewer
- ICLR 2025, Reviewer
- ICML 2025, Reviewer
- IJCV, Reviewer
🎖 Honors and Awards
- 2023 Full merit-based scholarship from Al-Ghurair Foundation for Education at Koç University
- 2021 Ranked 3rd in Computer Science Department at Koç University (CGPA: 3.96/4.0)
- 2020 Huawei Koç University Mobile Development Competition - 1st Place
- 2020 Project of the Year Award in Software Engineering Analysis and Design Course
- 2019 IEEEXtreme Programming Contest - Top 100 worldwide, 2nd in Turkey
- 2016 Honorable mention in Asia-Pacific Olympiad of Informatics (APIO)
- 2015-2016 Damascus ACM College Programming Contest - 1st Place (two consecutive years)
📖 Education
- 2023.08 - Present, PhD in Computer Science, Rice University, Houston, TX
- Advisor: Prof. Vicente Ordonez
- Focus: Multimodal generative modeling, computer vision
- 2018.09 - 2023.06, Bachelor in Computer Engineering, Koç University, Istanbul, Turkey
- Ranked 3rd in Computer Science Department
- CGPA: 3.96/4.0 (Full merit-based scholarship from Al-Ghurair Foundation)
- Relevant Coursework: Autonomous Driving, Advances in Deep Learning, Deep Unsupervised Learning, Deep Learning and Computer Vision, Introduction to Machine Learning, Natural Language Processing
💻 Professional Experience
Research Intern - Snap Inc., Creative Vision Team (Remote)
Summer 2024 - Present
- Working on cutting-edge research in computer vision and generative models
- Contributing to innovative projects in cross-modal generation and creative AI
- Collaborating with world-class researchers on diffusion models and multimodal AI
Machine Learning Engineer - CareX (Remote, Part-time)
April 2023 - August 2023, February 2021 - January 2022
- Developed AI-based methods for blood pressure estimation from fingertip videos
- Contributed to HRV estimation technology deployed in CareX’s SDK
- Implemented PyTorch and TensorFlow frameworks for model integration and visualization
Computer Vision Research Intern - KUIS AI LAB (Istanbul, Turkey)
July 2021 - July 2023
- Led research project on video modeling and manipulation using StyleGAN2 and Latent ODEs (VidStyleODE - ICCV 2023)
- Developed text-guided image manipulation methods using multimodal neural networks
- Implemented baselines for image manipulation based on CLIP and TokenGAN
Research Intern - IUI LAB (Istanbul, Turkey)
May 2020 - June 2021
- Designed self-supervised feedback system for sketch-based questions under Prof. Metin Sezgin
- Implemented novel transformer-based architecture using TensorFlow